ブログの関連記事をTF-IDFとコサイン類似度で生成する方法【文書の類似度】
こんにちは。
当サイト、パン工房はNuxt.jsを使って自作していますが、先日のリニューアルでブログの各記事の最後に載せている関連記事の生成方法を変えたことを書きました。いつか紹介できたらなんて書いていたので、今回紹介したいと思います。TF-IDFという、文書中の単語の重要度を計算する手法を用いた関連記事の作り方です。ちなみに自然言語処理の専門家でもなんでもありません。ネットで調べて作ったものなので正確性はご容赦ください。
ブログの関連記事
どのブログも各記事の下にその記事に関連する記事をいくつか載せていることが多いです。Googleなど検索エンジンで検索して入ってきた人が、その記事を読み終わった後すぐにサイト外へ出ていってしまうのを、関連した記事を見せることによって興味を持たせて引き止める効果があります。YouTubeの関連動画や、通販サイトの似た商品のリコメンドなんかも同様のものだと思っています。
前後の記事へのリンクを載せているブログも多いと思いますが、同じジャンルでも内容は関連していないことが多く、私はあまり使ったことがありません。特にこのブログの場合、ジャンルがバラバラで前後の記事が全く内容が関連しない記事であることが多いので、関連記事欄を重視しています。実際どの程度関連記事リンクが押されているのかは計測したことがないので、無駄な努力かもしれないですけどね。
リニューアル以前の関連記事ロジック
サイトリニューアル以前にもブログの関連記事欄はありましたが、もっと簡素なロジックで生成していました。各記事には1つのカテゴリ(リニューアル後は複数)と複数のタグを付けています。カテゴリは記事の内容がバラバラなことを踏まえたジャンル分け(生活、IT、ゲームなど)、タグはより細かに記事の内容をキーワードで表したもの(キングダムハーツ、LINE Pay、F1など)になっています。元々のロジックは、記事同士のカテゴリが同じものが近く、タグの重複が多いものが近くになるように重み付けをし、スコアが高い順に3つ表示するという方法を取っていました。
この方法のデメリットとして、カテゴリが曖昧な記事(ブログの技術要素について書いているのでITカテゴリにしたいが、ブログをリニューアルしたお知らせなので他のお知らせ記事に合わせてその他カテゴリにする、モバイルPASMOは鉄道で主に使うが生活を便利にするものなので鉄道カテゴリか生活カテゴリか迷う、など)だとそんなに似ていない記事でもスコアが高くなってしまうこと、タグ付けのキーワードの粒度や数によって重複の個数が変わってきてしまうことなどが挙げられます。記事の関連度合いは書き手が決める2要素程度では判定できないのです。
単語を抽出して類似度で順位付けしたい
自分で付けたカテゴリやタグでは記事同士の類似度を見るには不十分なので、まず記事の内容から特徴的な単語を抽出する必要があります。記事の中で何度も登場する単語、重要そうな単語が記事同士で似ていれば、その記事は似ていると判断するのです。本当はさらに単語同士の類似度(男、女は性別という観点で近い、電車、飛行機は乗り物という観点で近い、など)も考慮したかったもののそこまで勉強する余裕は無かったので、単語の一致度合いを見ることにしています。
ちなみに単語の抽出には形態素解析ライブラリを使います。今回は記事の内容について見たいので、「です」「の」「また」といった単語には興味がありません。形態素解析によって各単語の品詞が選べるので、名詞を抽出します。今後「単語」と言った場合は名詞のことだと思ってください。
今回記事同士の類似度計算に使ったのが、TF-IDF法とコサイン類似度です。単語の重要度の計算にTF-IDFを、各記事内の各単語の重要度を記事同士で比較し類似度を出すためにコサイン類似度を使用しています。
TF-IDF
TF-IDFは、文書中の単語の重要度を計算する手法で、TF(Term Frequency=単語頻度)とIDF(Inverse Document Frequency=逆文書頻度)をかけ合わせたものです。
TF
TFは文書内での単語の出現頻度を表しています。文書内の各単語について計算し、この値が大きいということは何度も言及される重要な単語である、と判断することができます。TFは次のように計算します。
.png?fm=webp&w=1280&q=60)
文書dにおける単語tのTFは、文書dにおける単語tの出現回数(n)を文書内の全ての単語の出現回数の合計で割ったものになります。つまり、文書内の単語のうちどのくらいがその単語か、ということです。その文書内で重要な単語であればそれだけ出現回数が多い、という考えに基づいています。
例えば、「私はクレープが好きです。特にイチゴとチョコとバナナが入ったクレープが好きです。」
という文書から「私」「クレープ」「イチゴ」「チョコ」「バナナ」という単語を抽出したとすると、TFは「クレープ」が2/6=0.33…、それ以外が1/6=0.16…となります。つまり、この文書の中では「クレープ」は「イチゴ」や「チョコ」よりも重要な単語であるということになります。
ただし、TFだけを使うと「私」「自分」「これ」といった、内容に関係なくよく使う単語の重要度が上がってしまいます。この記事もあの記事も「私」に関する記事だと思われてしまうのです。そこで組み合わせて使うのがIDFです。
IDF
IDFは、その単語を使う記事の全記事の中での希少性を表します。具体的には、全記事の中でのその単語を使う記事の頻度を計算し、その逆数の対数を取ります。IDFの値が大きいほど希少性の高い単語を扱う文書ということになります。IDFは次のように計算します。
.png?fm=webp&w=1280&q=60)
単語tのIDFは、単語tの出現する文書数DFtを全文書数Nで割ったもの(単語tが出現する文書の割合)の逆数の対数を取ったものです。各単語についてIDFを計算することで、その単語がブログ全体の中でどれだけ希少性が高いものなのかを計算することができ、「私」「これ」といった内容そのものに関わりにくい単語は希少性が低くなります。
例えば、
文書A「私はクレープが好きです。イチゴとチョコとバナナが入ったクレープが好きです。」
文書B「私はデザートではイチゴのケーキとクレープが好きです。でもダイエット中なので食べないようにしています。」
文書C「ベッドと枕を変えたら睡眠の質が良くなった友達の話を聞いて、私も枕を変えてみました。」
という文書でブログが構成されていたとすると、「私」のIDFはlog(3/3)+1=1、「クレープ」のIDFはlog(3/2)+1=1.17…、「枕」のIDFはlog(3/1)+1=1.47…になります。枕について書いた記事は3つのうち1つしかないので、希少性が高いというわけです。
TF-IDF
そして、TFとIDFをかけ合わせたものがTF-IDFになります。TF-IDFは、各文書の中で各単語について計算することができます。
.png?fm=webp&w=1280&q=60)
上の文書Aで「私」「クレープ」「イチゴ」「バナナ」についてTF-IDFを計算してみると、
私:1/6*(log(3/3)+1)=0.16…
クレープ:2/6*(log(3/2)+1)=0.39…
イチゴ:1/6*(log(3/2)+1)=0.19…
バナナ:1/6*(log(3/1)+1)=0.24…
となります。つまり、文書Aの単語の中では「クレープ」>「バナナ」>「イチゴ」>「私」という順に重要な単語であると判断ができるわけです。
文書Cの「私」「枕」でも試してみます。
私:1/8*(log(3/3)+1)=0.12…
枕:2/8*(log(3/1)+1)=0.36…
となり、「私」よりも「枕」のほうが遥かに重要な単語であることが分かります。
コサイン類似度でTF-IDFの類似度を計算
ここまでは各記事の中での単語の重要度をTF-IDFで計算してきました。しかし欲しいのは記事同士でどれだけ内容が関連しているかの数値です。そこで登場するのがコサイン類似度です。
コサイン類似度とは
コサイン類似度は、2本のベクトルがどの程度同じ方向を向いているかを表しています。2本のベクトルのなす角のコサインで計算できるため、1に近いほど類似度が高いことになります。ベクトルaとベクトルbのコサイン類似度は次のように計算します。
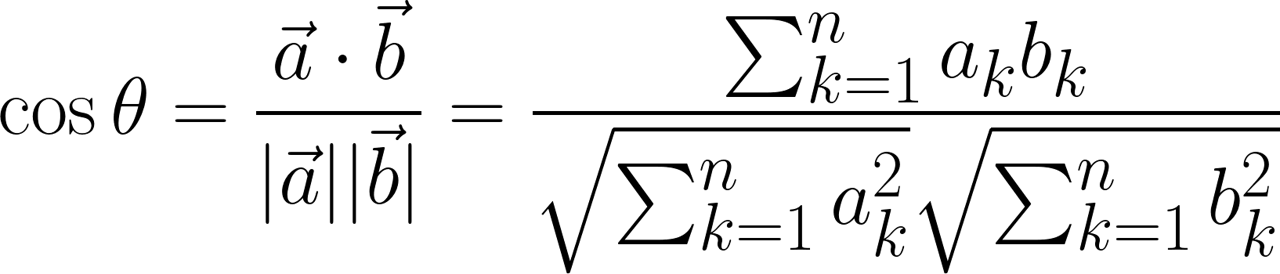
いわゆる内積の公式を変形したやつですね。
全単語のTF-IDFを文書に対するベクトルにする
というわけでコサイン類似度を使うために、全単語のTF-IDFを文書ごとにベクトルの形にしていきます。まず全単語のTF-IDFを表にまとめるとこのようになります。
| 私 | クレープ | イチゴ | チョコ | バナナ | デザート | ケーキ | ダイエット | ベッド | 枕 | 睡眠 | 質 | 友達 | 話 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 文書A | 0.16 | 0.39 | 0.19 | 0.19 | 0.24 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 文書B | 0.16 | 0.19 | 0.19 | 0.00 | 0.00 | 0.24 | 0.24 | 0.24 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 文書C | 0.12 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.18 | 0.36 | 0.18 | 0.18 | 0.18 | 0.18 |
こうするとそれぞれの文書のベクトルを作ることができます。
文書Aベクトル=(0.16, 0.39, 0.19, 0.19, ...)
のような形です。ここまで来たら後はコサイン類似度を計算するだけです。計算すると、
文書Aと文書Bのコサイン類似度=0.53
文書Aと文書Cのコサイン類似度=0.20
文書Bと文書Cのコサイン類似度=0.23
となります。文書Aと文書Bはかなり似ていて、文書Bは文書Aよりもほんの少しだけ文書Cに似ているという計算結果になりました。文書Cが文書Aにも文書Bにも関係ない話題なのでちょっと例が悪かったかもしれませんが、文書中の単語の数によって少しだけ差が出ましたね。
基準となる記事以外の記事を類似度順に並べる
あとは閲覧している記事について、それ以外の記事とのコサイン類似度を全て計算し、値が大きい順に並べれば関連記事欄の完成です。

このような感じで良い感じの関連記事が並んでいます。タイトルだけ見ても関連しているように見えますが、内容もちょうどよく関連したものが選ばれていると思います。
というわけで今回は、TF-IDFとコサイン類似度によるブログの関連記事の生成方法を紹介しました。正直数学は苦手なほうですが、意外と何とかなるものですね。ちなみにこれまで紹介した手法をプログラム化したものはNode.jsで書いているわけですが、なかなか汚いものになっておりお見せできません。ライブラリを使えばもっと簡素に書けたかもしれませんが、内部ロジックが見れるのもそれはそれで良いので良しとします。ちなみに記事が増えるほど全単語数が膨れ上がっていくので計算量が膨大になるところがデメリットになってきます。
この記事の関連記事は何が表示されているでしょうか。
それではまた。